It encodes itself using Visible Input Nodes, and the Visible Output Nodes are decoded using Hidden Nodes, in order to be identical to the Input Nodes. It is not a pure Unsupervised Deep Learning algorithm, but it is a Self-Supervised Deep Learning algorithm.
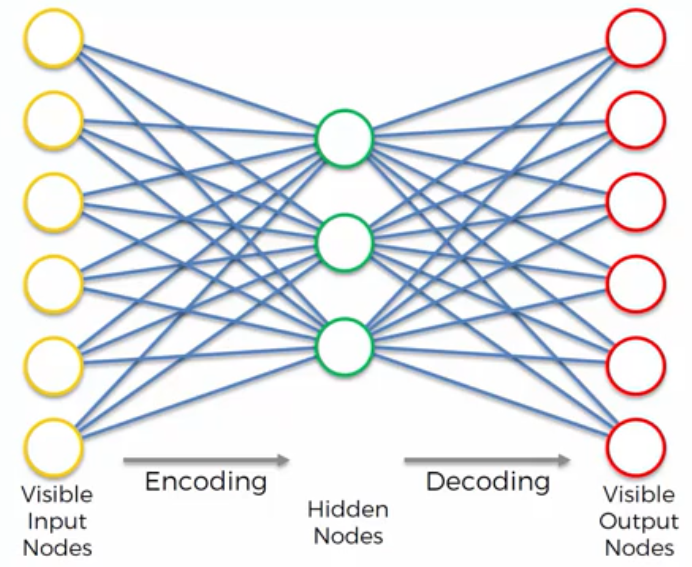
Auto Encoders can be used for Feature Detection. Once we have encoded our data, the Hidden Nodes also called Encoder Nodes, will be represent certain features which are important in ur data. For example, these features, founded via Auto Encoder, can be used to build a powerful Recommender System.
From the figure below, we are using an auto encoder for movies. These are movies that person have watched and rated. First, we have to train the Auto Encode, and from the figure above, we have to reduce four values (from movie 1 to movie 4) in a smaller space of the Hidden Layer (also known as Encoder Layer).
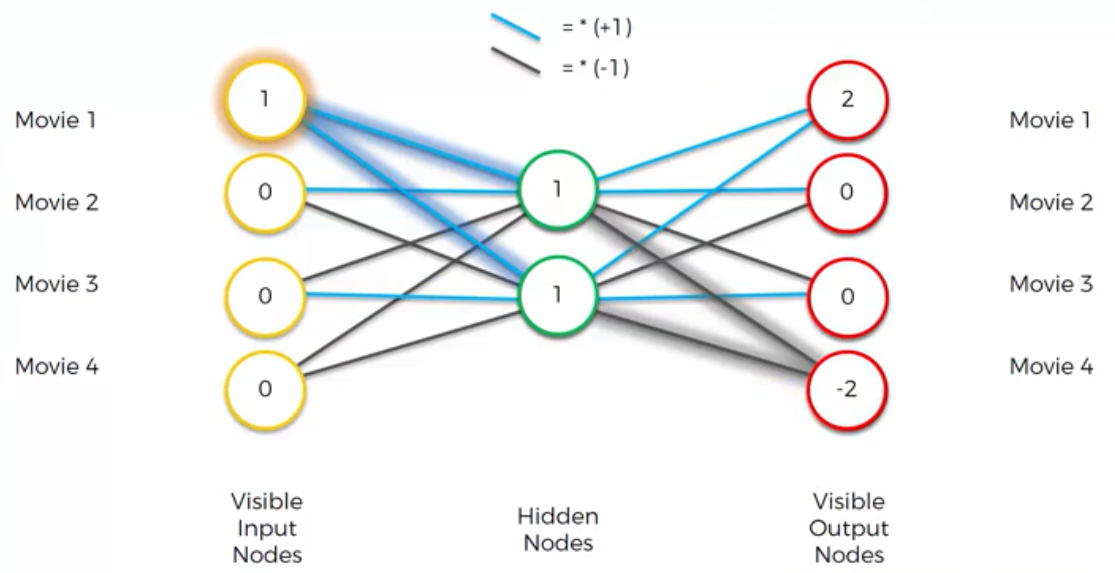
We colored the connections in blue=multiplication by 1 and black=multiplication by -1. In reality the Hyperbolic Activation Tangent Function is usually used in Auto Encoders.
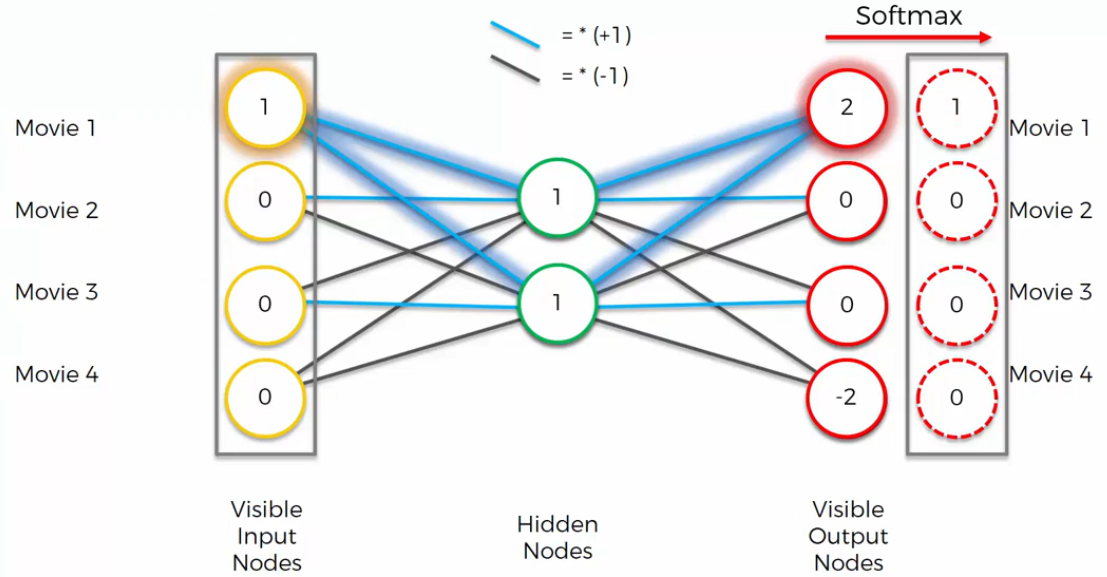
In the figure above, we have in input Movie1=1 and the Other Movies=0. In this case the Hidden Nodes are both to 1 because the blue connections are multiplied by 1, and the zeros always just add zero. Now, having the Hidden Nodes, we can calculate the Output Nodes. The Top Right Output Node is 1+1=2, the Second Output Node is 1 -1=0. The same is for the Third Output Node. Last Output Node is -1-1=-2. This is a preliminary output, because in the Auto Encoder we also have a Softmax Function on the end. Basically the Softmax Function takes the highest value, in this case 2, and it turns that into 1, and everything else into 0. And as we can see from the figure below, after the Softmax Function, we have in Output the same result that we have in Input.
We can encode the Input into a small format where we just have Two Hidden Values. There are much more detail in the article: Neural Networks Are Impressively Good At Compression.
How to Train an Auto Encoder STEP - 1 We start with an array where the observations correspond to the users, and the features correspond to the movies with a rating from 1 to 5, and 0 if no rating. STEP - 2 We put all rating per user in a vector x, and we encode it into a vector z of lower dimensions by mapping function. STEP - 3 The vector z is decoded into the output vector y of same dimensions as vector x. STEP - 4 The reconstruction error d(x, y)=||x-y|| is computed in order to minimize it. STEP - 5 The error is back-propagated, and weights are updated accordingly on how much they are responsible for the error. Then, when the whole training set passed through the ANN, that makes an Epoch.
Overcomplete Hidden Layer There are lots of variations in Auto Encoder,and Overcomplete hidden Layer is one of the most variations of Auto Encoder. It consists to have more nodes in the Hidden Layer, and this is especially used when we have to extract more features. This is a great idea but there is a problem because if we have for example four inputs, having a Hidden Layer greater of the Input Layer, we have extra nodes that are not being used. In order to solve this problem, there are two different approaches: 1 - Sparse Autoencoders. 2 - Denoising Autoencoders.
Sparse Autoencoders As explained above, we are going to create an Autoencoder with a Hidden Layer with more nodes than the Input Layer. The reason for that is we want to extract more features. Sparse Autoencoder is used a lot, and it is an Autoencoder where a Regularization technique is used . More precisely, it introduces *sparsity in order to prevent overfitting. It introduces a penalty on the Loss Function** that doesn’t allow the autoencoder to use all the nodes in its Hidden Layer every single time, but it can only use a certain number of Hidden Nodes. By doing that, we are extracting features but not at any given pass. Additional reading is: Deep Learning Tutorial Sparse Autoencoder.
Denoising Autoencoders This is another Regularization Technique, to face the problem of when we have more nodes in the Hidden Layer than in the Input Layer and therefore the Autoencoder can lead us to overfitting. The Denoising Autoencoders remove the Input nodes and replace it with a new version of Input values. It takes there inputs and randomly, and turns some of them into zeros.
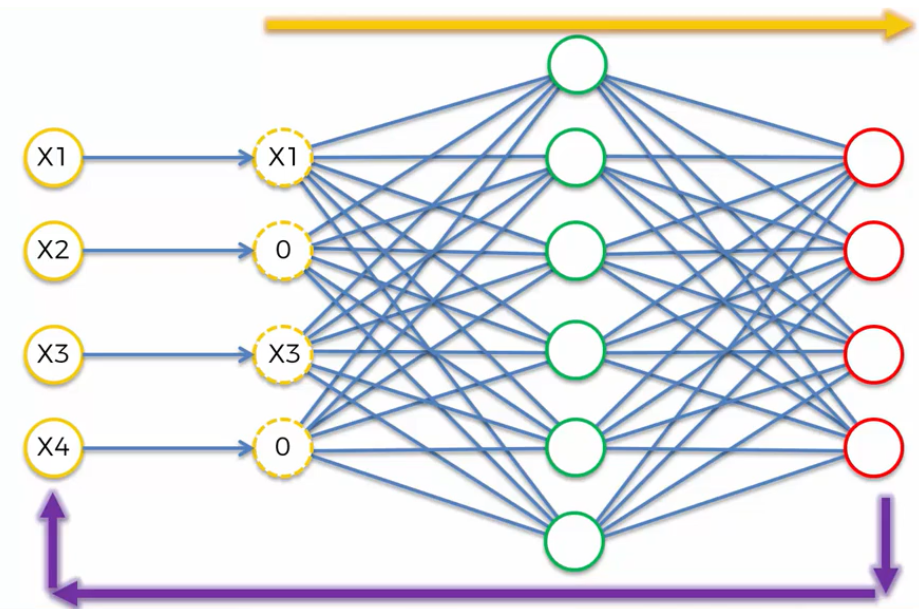
Crucially, we calculate the Output based on the new Input Values (with zeros), but we compare the Output with the Original Input Values (without zeros). This helps to face the problem of overfitting. This Autoencoder is called Stochastic Autoencoder, so basically it depends on this random selection of which values are going to be zero. Additional reading is: Extracting and Composing Robust Features with Denoising Autoencoders.