This article is a summary of the StatQuest video made by Josh Starmer. Click here to see the video explained by Josh Starmer.
The Boosting and Ensemble Learning concepts can be applied to many Machine Learning models: it is a Meta Algorithm used to convert many weak learners into a strong learner in order to achieve good performance in supervised problems.
Why Ensemble First of all, ensemble often have lower error than any individual method by themselves. It has also less overfitting leading us to a better performance in the test set. Each kind of learners that we might use has a sort of bias. Combining all of them, can reduce this bias.
Boosting Boosting trains the models by sequentially training a new simple model based on the error of the previous one. This procedure tends to discover the data points that are hard to predict. In the end, it sums all the models in a weighted combination, and this procedure is known as Scaling Up Complexity. Combining weak learner models that are not able to learn complex function, we can convert them in an overall much more complex classifier. So, the combination of several simple models produces an overall decision that is more complex. This process correspond to minimize the Loss Function (Cost Function). A classic example for boosting classification is the ADA Boost: Adaptive Boosting Algorithm.
Adaptive Boosting in Random Forest In a Forest of Trees made with ADA Boost the trees are usually just One Node with Two Leaves that are called Stump, so it is a Forest of Stump. A Stump is not good to make a classification, simply because it doesn’t take advantage of all the features available, Stumps are technically Weak Learners. In contrast, in Forest of Stumps made with Ada Boost, some Stumps get more importance in the final classification than other Stumps. Crucially, each Stump comes in a precise order, so, the error of the first Stump influence the error of the second Stump and so on. In other words: ADA Boost combine weak learners to make classification that learn from the mistakes made by the previous Stump.
The procedure starts to give a weight to each observation.
1 - At the start, all observations get the same weight which is 1/total number of samples. That make the sample equally important.
2 - We start calculating the Stump separately for each feature.
3 - The Stump with Lower Gini Index will be the First Stump in the forest.
4 - Then, we use the Total Error of the Stumps to determine the amount of importance of the Stump.
5 - The Amount of Importance, aka Amount to Say, is calculated by: ½ log (1-Total Error)/Total Error.
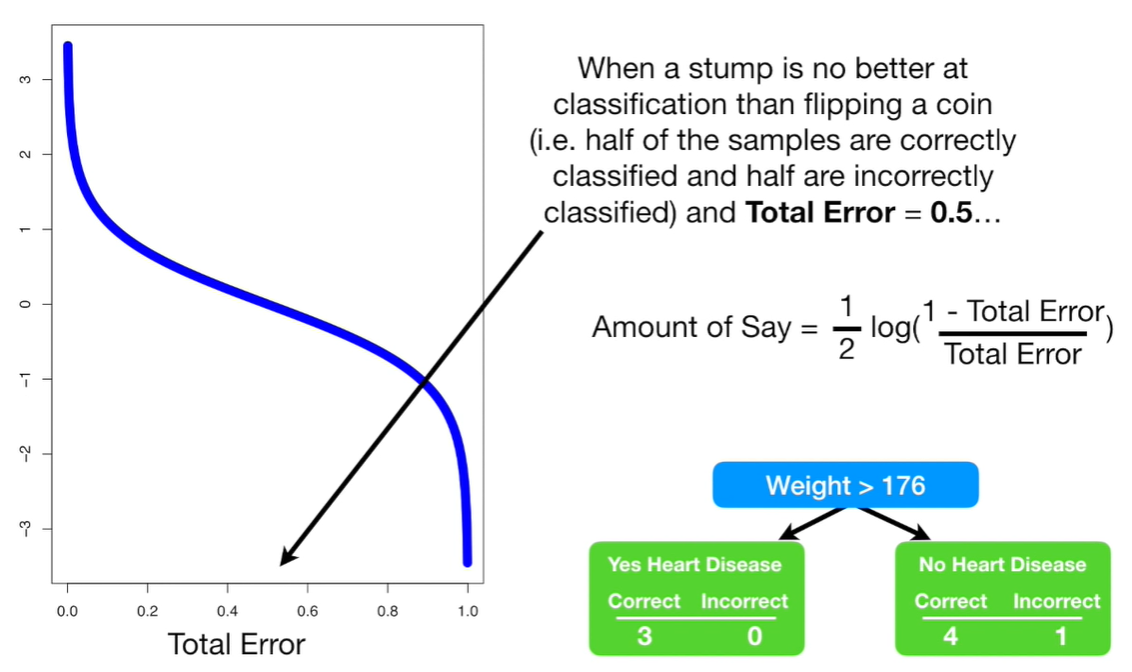
When a Stump is no better at classification than flipping a coin, the total error is equal to 50%. When a Stump does a terrible job the error is close to 100%. And, if a Stump makes a mistake, we have to emphasize the need for the Next Stump to correct this error of classification. We do that, increasing the weight of this Stump and at the same time we decrease the weight of the other stump.
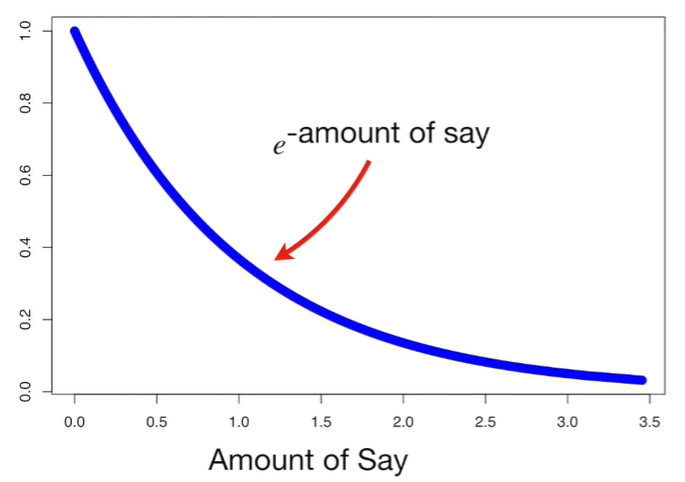
The blue line of the graph below is e^amount of say. When the amount of say is large, the Stump did a good job in classifying sample.
Drawback of Ensemble 1 - Time and computation expensive. 2 - Hard to implement in real time platform. 3 - Complexity of the classification increases.
Advantages of Ensemble If the first two Principal Components of the PCA would not create a very accurate representation of the data, in this case could be better to use an Ensamble Approach.