The Root Mean Square Propagation RMS Prop is similar to Momentum, it is a technique to dampen out the motion in the y-axis and speed up gradient descent. For better understanding, let us denote the Y-axis as the bias b and the X-axis as the weight W. It is called Root Mean Square because we square the derivatioves of both w and b parameters.
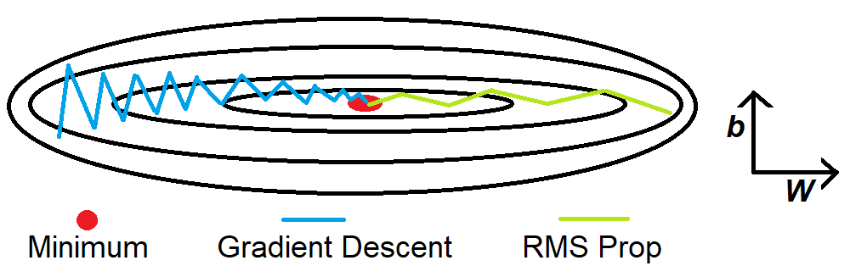
The intuition is that when we divide a large number by another number, the result becomes small. In our case, the first large number is db and the second large number that we use is the weighted average of db². We introduce two new variables Sdb and SdW, to keep track of the weighted average of db² and dW². The division of db and Sdb results in a smaller value which dampens out the movement in the y-axis. The Ⲉ is introduced to avoid the division by 0 error.
\[ \begin{aligned} S_{d W} &=\beta S_{d W}+(1-\beta) d W^{2} \\ S_{d b} &=\beta S_{d b}+(1-\beta) d b^{2} \\ W &=W-\alpha \cdot \frac{d W}{\sqrt{S_{d W}}}+\epsilon \\ b &=b-\alpha \cdot \frac{d b}{\sqrt{S_{d b}}+\epsilon} \end{aligned} \]
The idea is to slow down the learning on the y-axis direction and speed up the learning on the x-axis direction. On each interatioin t the derivatives dw and db are computed on the current mini-batch. It is also perfomed the exponentially weighted average called SdW and Sdb. Now, the exponentially weighted average parameter SdW is relatively small and so we are deviding by a small number to obtain the weight. The alpha parameter is the learning rate and the Ⲉ is introduced to avoid the division by 0 error. On the contrary, Sdb is relatively large and it helps to slow down the updates vertical dimention b. In fact looking at the figure above, the derivative in the orizontal dimenstion is aways small and the derivative on the vertical dimention is large. The net effect is to speed up the veritical learing and at the same time slow down the vertical learning. The result is the green line of th figure above.
Reference: coursera deep neural network course