In Batch Gradient Descent on every interation we go through the entire training set. From the figure below we can see the cost function J on the left a batch gradient descent that decrease every single interation. On the right we have the cost function J of a mini-batch gradient descent where in every interatin our processing in training on a different train-set; that is why the loss function J is going to be a little noisier.
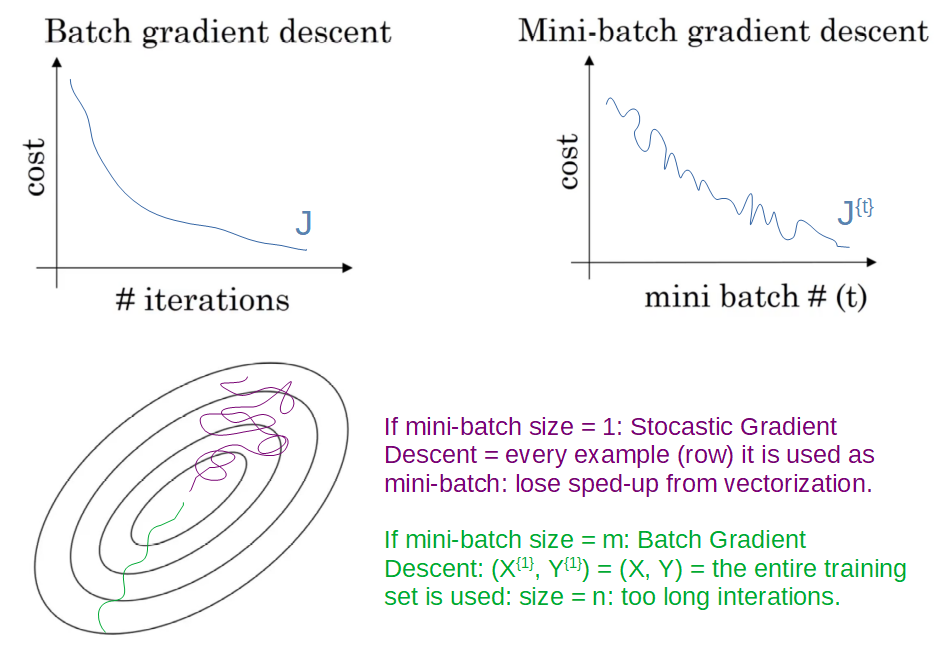
The most important parameter we have to choose is the size of the mini-batch called m. What works best is to use something in-between Mini-batch size not to big or too small in order to have fatser learing. Moreover, we have more vectorization and we make progress without needing to wait to process the entire training-set. The in-between Mini-batch size doesn’t always garantee head toward the minimim, but it tends to head more consistently on the minimum. Some guidelines in choosing the size of the in-between Mini-batch size are: 1 - with small training-set: use batch gradient descent 2 - with big training.set: mini-batch size is typical in the range of the power of 2 (64, 128, 256, 512) 3 - make sure that mini-batch fits in CPU/GPU memory.
The size of in-between Mini-batch size is an hyperparameter and it is common to try few different powers of 2 between the range that goes from 64 to 512 and then pick one that makes out gradient descent as efficient as possible.
Reference: coursera deep neural network course